If you’re here, you probably already know what Text2SQL means, but if you don’t, I’ll explain it briefly: Text2SQL is a language model capable of converting a natural language query into a structured SQL query. For example, a natural language query like “What are the songs by Judas Priest from the Painkiller album?” can be translated into:
SELECT music, band, album
FROM musics
WHERE band = 'Judas Priest' AND album = 'Painkiller';
As you can see, this is a simple question that can be expressed using relational algebra and doesn’t require complex reasoning, the resulting table from the query is enough. This is fantastic from the perspective of democratizing data access within a company, allowing people who don’t know SQL to still interact with the data.
However, there’s more we can do today. With RAG (Retrieval-Augmented Generation), large language models (LLMs) can answer questions about topics that weren’t necessarily part of their training data. This is possible thanks to the following process:
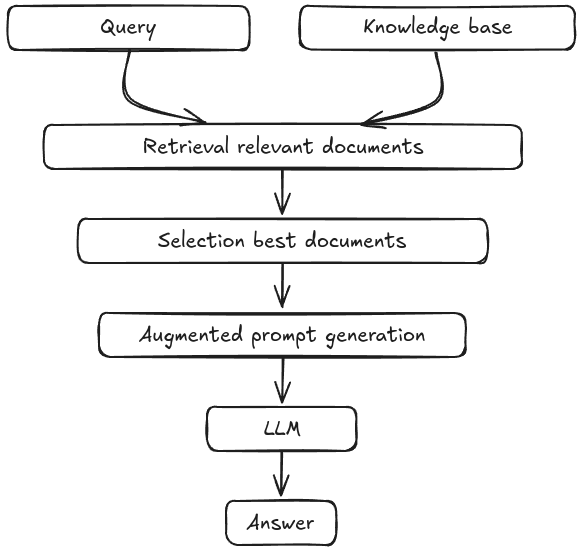
The knowledge base can be made up of various types of documents—PDFs, DOCX files, TXT files, etc.
With RAG, something very interesting happens: instead of just returning a snippet from a document, which may or may not contain the relevant information, RAG generates a concise and specific answer to the question, based on external knowledge that lies outside the model’s training data. This contrasts with the older method of simple retrieval, which was more common in the past.
In Text2SQL, we have a limitation: it can’t handle complex questions. It can only be used to answer a small subset of queries that can be directly translated into structured queries (relational algebra).
But what if we combined the strengths of Text2SQL with the capabilities of LLMs? This is where a new paradigm called TAG (Table-Augmented Generation) comes in, unifying the interaction between LLMs and databases. It enables responses to questions that require more sophisticated domain knowledge, world knowledge, computations, and semantic reasoning.
In this system, it’s possible to answer not only the subset of questions that Text2SQL can handle, but also those that RAG can respond to, while adding an extra layer of complex reasoning. TAG allows LLMs and database management systems to work together more effectively, going beyond simple information retrieval or direct SQL queries.
TAG introduces three key steps: query synthesis, query execution in the database, and response generation using the LLM’s semantic reasoning over the returned data. This enables the model to handle questions that require a more complex combination of textual reasoning, calculations, and world knowledge, something previous approaches couldn’t achieve on their own.
Imagine the following scenario: you are an executive at a cosmetics company and need to guide your research and development team to prioritize improvements on certain aspects of a product that has received numerous negative reviews. You have thousands of reviews for this product stored in a database table. The question is: “Among the negative reviews of product X, what are the most frequently criticized features?” However, this table does not have a column indicating whether a review is positive or negative.
This is where TAG comes into play. Not only can it retrieve this data, but the LLM can use its semantic reasoning to automatically classify each review as positive or negative, filtering out only the negative ones. This happens during the query synthesis step (as shown in the query below). The query is then executed, and the returned data is analyzed, generating a report that highlights the most frequently mentioned negative aspects of the product, allowing these areas to be prioritized. The decision-maker receives a comprehensive, automated analysis, enabling them to direct the R&D team’s efforts more effectively, based on concrete data.
SELECT review
FROM reviews
WHERE LLM('{review} is negative') = 'True';
This is possible because TAG (Table-Augmented Generation) allows user-defined functions (UDFs) with LLM support to be executed directly within SQL queries. The LLM is invoked for each row, using its semantic reasoning to identify the negative reviews.
TAG makes this entire process possible without the need to create new columns in the database or manually classify the reviews.
For more information about TAG, I invite you to read the article referenced below. Thanks for reading!